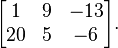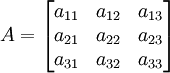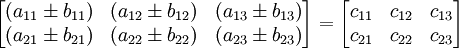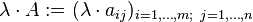Pengertian Stack pada Struktur
Data adalah sebagai tumpukan dari benda, sekumpulan data yang seolah-olah diletakkan di
atas data yang lain, koleksi dari objek-objek homogen,
atau Suatu urutan elemen yang elemennya dapat diambil dan ditambah hanya pada
posisi akhir (top) saja. Stack pada Struktur
Data dapat diilustrasikan dengan dua buah kotak yang ditumpuk, kotak yang satu akan ditumpuk diatas kotak
yang lainnya. Jika kemudian stack 2 kotak tadi, ditambah kotak ketiga, keempat,
kelima, dan seterusnya, maka akan diperoleh sebuah stack kotak yang terdiri
dari N kotak.

Stack bersifat LIFO (Last In First Out) artinya Benda yang terakhir
masuk ke dalam stack akan menjadi yang pertama keluar dari stack
Operasi-operasi yang biasanya tredapat pada Stack yaitu:
1. Push : digunakan untuk
menambah item pada stack pada tumpukan paling atas
2. Pop : digunakan untuk
mengambil item pada stack pada tumpukan paling atas
3. Clear : digunakan untuk
mengosongkan stack
4. IsEmpty : fungsi yang
digunakan untuk mengecek apakah stack sudah kosong
5. IsFull : fungsi yang
digunakan untuk mengecek apakah stack sudah penuh
Cara mendefenisikan Stack dengan Array of Struct yaitu:
1. Definisikan Stack dengan menggunakan
struct
2. Definisikan konstanta MAX_STACK untuk
menyimpan maksimum isi stack
3. Buatlah variabel array data sebagai
implementasi stack
4. Deklarasikan operasi-operasi/function di
atas dan buat implemetasinya.
contoh :
//Deklarasi MAX_STACK
#define MAX_STACK 10
//Deklarasi STACK dengan struct dan array
data
typedef struct STACK{
int top;
char data[10][10];
};
//Deklarasi/buat variabel dari struct
STACK tumpuk;
Inisialisasi Stack
Pada mulanya isi top dengan -1, karena array
dalam C dimulai dari 0, yang berarti stack adalah kosong.
Top adalah suatu variabel penanda dalam STACK
yang menunjukkan elemen teratas Stack sekarang. Top Of
Stack akan selalu bergerak hingga mencapai MAX of STACK sehingga menyebabkan
stack penuh.

Ilustrasi Stack pada saat inisialisasi
IsFull berfungsi untuk memeriksa apakah stack sudah penuh atau tidak. Dengan
cara, memeriksa top of stack, jika sudah sama dengan MAX_STACK-1 maka full,
jika belum (masih lebih kecil dari MAX_STACK-1) maka belum full.

Ilustrasi Stack pada kondisi Full
IsEmpty berfungsi untuk memeriksa apakah stack masih kosong atau tidak.
Dengan cara memeriksa top of stack, jika masih -1 maka berarti stack masih
kosong.

Push berfungsi untuk memasukkan elemen ke stack, selalu menjadi elemen
teratas stack (yang ditunjuk oleh TOS).
Tambah satu (increment) nilai top of
stack lebih dahulu setiap kali ada penambahan elemen stack.
Asalkan stack masih belum penuh, isikan data
baru ke stack berdasarkan indeks top of stack setelah diincrement sebelumnya.

Pop berfungsi
untuk mengambil elemen teratas (data yang ditunjuk oleh TOS) dari stack.
Ambil dahulu nilai elemen teratas stack
dengan mengakses top of stack, tampilkan nilai yang akan dipop, baru dilakukan
decrement nilai top of stack sehingga jumlah elemen stack berkurang.

Printberfungsi untuk menampilkan semua elemen-elemen stack dengan cara
looping semua nilai array secara terbalik, karena kita harus mengakses dari
indeks array tertinggi terlebih dahulu baru ke indeks yang kecil.


Operasi Push
void Push (NOD **T, char item)
{
NOD *n;
n=NodBaru (item);
n->next=*T;
*T=n;
}
Operasi Pop
char Pop (NOD **T)
{
NOD *n; char item;
if (!StackKosong(*T)) {
P=*T;
*T=(*T)->next;
item=P->data;
free(P);
}
return item;
}
create berfungsi untuk membuat sebuah
stack baru yang masih kosong.